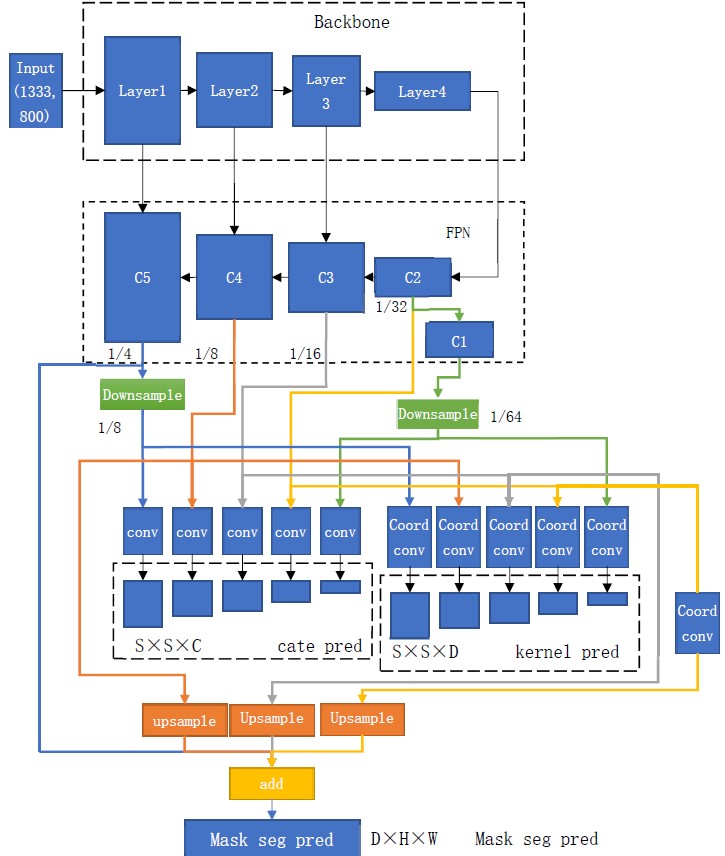
solo系列网络是由Xinlong Wang提出的单阶段实例分割网络。其搭建在mmdetection库中。solov2主干网络如下图所示:
Tensorrt实现solov2加速步骤如下所示:
1、修改solo中tensorrt或onnx不支持的层。solo原生代码中采用的group normalization层在onnx和tensorrt中支持性不高,会导致模型转换错误,因此将模型中所有group normalization层替换为batch normalization层。因为具体替换了模型的结构,因此还需对模型进行重新训练。
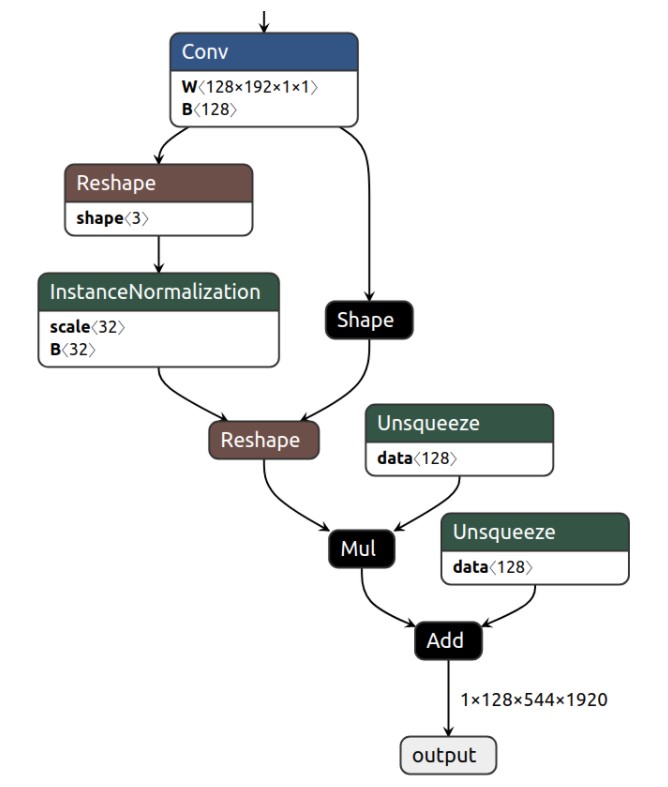
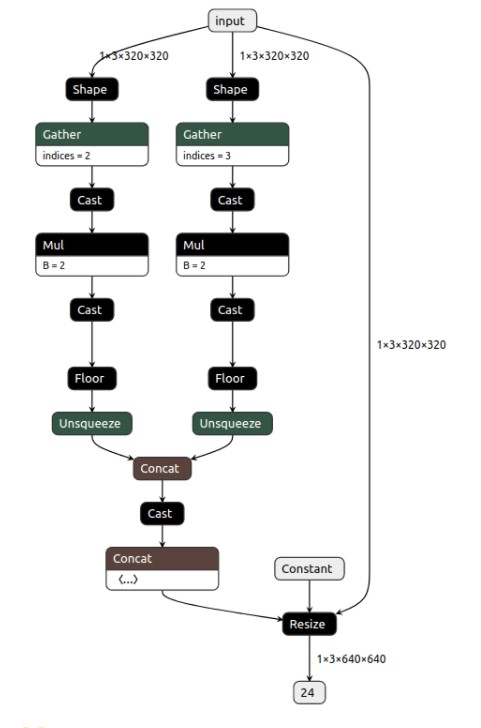
2、进行pth模型到onnx模型的转换。pytorch1.3对应的onnx版本为1.6,其upsample层需具体转换尺寸,不然会在转tensorrt的过程中报错。此外,solo采用了较为特殊的coordconv,onnx不支持其采用的torch.linsapce操作,因此我们将coord中指明方向的两层保存为具体参数直接读取使用,具体代码为:
1 | import torch |
转换onnx的具体代码如下所示:
1 | import argparse |
3、进行onnx模型到tensorrt模型的转换。
1 | import pycuda.driver as cuda |